
|
Autumn 1997
|
Everybody is talking about them. New products are being brought to market to enable you to take advantage of them. But what exactly are data warehouses? Are they just the latest in a series of trendy concepts, or do they offer real solutions to real business problems?
In the first two articles, reprinted by kind permission, Sally Hober of TAG Consulting Inc explains the concepts behind data warehousing and why they are relevant to your business.
The second article, covering best practices and potential pitfalls, will appear in our winter issue.
With the masses of software tools being introduced to help you design, develop and deploy data warehouses, it seems odd that data warehousing is more of a software architecture than software. Yet experience has shown that the cost of most successful projects consists of 80% services and 20% software. Although, today, many software vendors are producing powerful tools that will help reduce this ratio, the truth is that data warehousing is a human resource intensive project.
The purpose of this article is to focus on the process involved with building a data warehouse instead of the tools that could be used. Specifically, I'll define what a data warehouse and data mart are and why you would want to build them. Then I'll cover the steps you would take to design and deploy your data warehouse.
What is a Data Warehouse?
The most commonly agreed upon definition of a data warehouse is "a subject-oriented, integrated, time-variant, non-volatile collection of data in support of management's decision making process".
As clear as the meaning of these words is, we'll take another, less academic approach. A data warehouse is a database containing historical corporate information that is tightly integrated with the operation database. You can have your data warehouse in a different database than your day-to-day database, but the flow of data between these databases should be automated. The data warehouse should be capable of displaying 'point-in-time' information even after the point has passed. In other words, if you realigned your sales territories, the data warehouse should be able to view historical data in the context of both the old and new alignment. Finally, the data that goes into the data warehouse should be static and dependable. There is nothing that annoys users more than the possibility that historical information can change based on factors beyond their control.
The integration of the data warehouse with the operational data means more than first glance might indicate. A data warehouse should include all data available to an organisation regardless of where the data is located. On an academic level, this encompasses drawings, documents, charts, graphs, maps and photographs, etc.
While personally, this seems a little unrealistic, there is one area of concern for many companies looking at data warehousing. The advent of Microsoft Access and FoxPro and Borland's Paradox meant that for the first time, sophisticated data storage and retrieval capabilities were in the hands of the people who needed it. And the personal database flourished, sprouting up in many different forms throughout the corporation.
Unfortunately, some significant business information is encoded in these databases. I have seen royalty payments calculated from information stored on an Excel spreadsheet. The budgetary requirements for many companies can be found on spreadsheets and databases. And this information, while crucial for the company and the success of the data warehouse cannot be easily integrated with the operational data. Certainly a conundrum for our intrepid data warehousing pioneers.
According to the strict definition of data mart, there cannot be a data mart without first creating a data warehouse. Other definitions define a data mart according to its size (i.e. smaller than a data warehouse but bigger than a single file). Successful IS managers are redefining the data mart based on what works. They are building single subject data warehouses and calling them "data marts" with the long run plan being to tie all the marts together to create the data warehouse. This practice started because many data warehouse projects were failing, regardless of multi-million dollar budgets, due to the sheer size of the task. Data mart projects, on the other hand, were producing measurable results within a couple of months.
For those of you heaving a sigh of relief, a word of caution. Data marts without data integration can cause a lot of problems. Simply off-loading operational data to a separate database where the tools used to view the data are more user-friendly is not a new solution. In fact, many in the MultiValue market place claim that by using retrieval tools like English, Access and Retrieve, users can already get the information they need from the existing database. See the next section for a refutation of this belief. And the basic problem of integrating data from different sources, including different sources within your database, has not been resolved.
OLTP vs. OLAP: Why do we Need a Data Warehouse?
The underlying reason for building a data warehouse/mart has grown from executives' demands for information about their company. To make the best decisions for their companies future, executives must have access to up-to-data and accurate information and the tools to analyse it. Staying competitive and maximising profits requires looking at historical and current performance and future trends. This demand for business information is not new. The data warehouse solution that is being proposed here is.
Most companies have a valuable hidden resource in their existing data. The resource is hidden because the information executives need can't be accessed easily. For example, a manufacturing company hired an executive whose main responsibility was to get their inventory under control. The company had millions of dollars in inventory that had been on the shelf for a year or longer, but they had a huge sales backlog for other products. The executive started the inventory control project by requesting various reports by the IS department. Days later he had his reports. Unfortunately, his response was to ask for variations on the original report or to completely change the definition of the terms used in the report. A week later, the new reports were produced and the cycle started up one more time.
Is this scenario unique? Of course not. In fact, the surprise would be if this cycle didn't exist. There are two basic causes for this situation. The first is that the communication process between the user and the IS department is typically quite challenging. Forgetting for a moment the difficulty that any two people might have getting a point across, the point-of-view of the user is normally radically different to that of the IS programmer. But that's the topic of a completely different article.
Another problem are could be the design of the operation database. Most databases were designed to handle OLTP (on-line transaction processing) applications. We concern ourselves with the design redundancy of the data and the speed that users see as the enter the data. The executive, however, was looking for an OLAP (on-line analytical processing) system. With OLAP, the focus is on retrieving and displaying the data as quickly and as visually as possible. While both types of processing are important to the success of any business, there is a problem when the reside on the same system and use the same database design. The result is that either OLTP or OLAP transactions are given priority (which is detrimental to the loser) or the efficiency of the system is compromised.
Since it is not feasible for a company to abandon OLTP requirements and re-engineer for OLAP, the IS department has to create, manage and support a dual database environment. The two databases are an operational database and an evaluational database. Operation data are the data used to support OLTP. Evaluational data, (the data warehouse) is used to support OLAP. By creating the second database, IS can maximise the effectiveness of both. The differences between the two databases are characterised by the type of data contained within and how the data is used. Figure 1 lays out these differences.
| Operational | Evaluational | |
| Volatility | Dynamic | Static |
| Currentness | Current | Historic |
| Instance | Single time | Time variant |
| Granularity | Primitive and detailed | Derived and summary |
| Updates | Continuous, random | Scheduled, periodic |
| Structure | Static | Dynamic |
| Normalisation | Highly normalises | Moderately Normalised |
| Indexes | Minimum indexes | Maximum indexes |
| Flexibility | Low, repetitive | High, heuristic |
| Performance | High, quick response | Low, long response |
Figure 1 - Operation vs. Evaluational Databases
How to Build a Data Mart
As you can see from the title of this section, we are going to focus(for what we believe are fairly obvious reasons) on the process of constructing a data mart.
Before any data mart project is begun, I strongly recommend that the participants undergo some level of training. Two sources of self education are Micheal Bracket's The Data Warehouse Challenge: Taming Data Chaos and William Inmon's Building the Data Warehouse. Bracket's book provides a new perspective for data modelling and stresses how important it is that you don't proceed with a data warehouse project without data modelling. Inmon's book provides a different approach to data modelling and also presents an overview of some of the challenges waiting for you.
Data mart design is very different from the typical system development life cycle (SDLC). The classic SDLC is driven by the needs of the user. It consists of requirements gathering, analysis, design, programming, testing, integration, and implementation. On the other hand, the data mart development life cycle is data driven. Because the cycle is data driven, the starting point to model the data. As well, the steps you need to go through to create the data mart are not linear. The process is iterative, so plan on operating in a type of feedback loop where the requirements for the next step in the process is determined by the results of the current step. And be prepared for the state of uncertainty that comes along with this method.
Data Modelling
The purpose of data modelling is to identify the data required by a process
and to define the relationship between the data. There are three steps in the
typical data modelling process.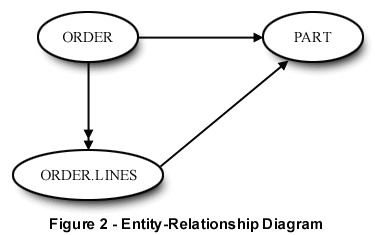
Entity relationship (E-R) diagrams, or high level modelling, depicts entities in the real world and the relationships between the entities. Although there are a number of different ways to represent E-R, we use a fairly traditional standard in which the entities are shown in ovals and the relationship between them is depicted by the lines and arrows. Figure 2 illustrates an E-R diagram for a very simple order entry system.
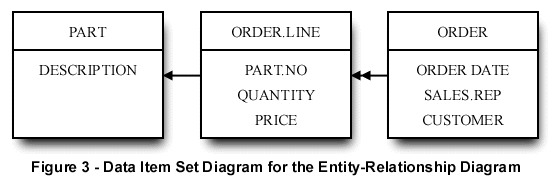
Mid-level modelling depicts a data item set (DIS) for each entity in the entity relationship diagram. The mid-level model shows both primary and secondary grouping of data, the type for each data item and the relationship between the entities. Figure 3 shows the DIS diagram for the E-R diagram in Figure 2.
The lowest level is the physical data model. This extends the mid-level model that includes concepts such as keys, as well as to take advantage of the features of the database on which the data model will be implemented. Data modelling should be done for both the existing database and the data mart database.
Although it may seem redundant, modelling the existing data should not be skipped. There is typically a lack of awareness and understanding of the current data. Fields which are not being maintained and free-form text fields which are used to store critical information are quite common, especially in the MultiValue database world where adding another field is easy and there is no strong data typing in the database.
Modelling the data mart is equally important. The data mart data model is a blue print of the mart, so it makes little sense to start without it.
Data modelling produced not only a clear understanding of existing data and the data mart data, but also the beginnings of the metadata. Metadata is information about the data in the database. We are already familiar with the concept (if not the term) through our use of dictionaries. A dictionary item is nothing more than the definition of attributes associated with a field in a database. Metadata includes, but is not limited to: the source in the operation database for the field, hierarchical relationships between fields, a description of the field, formatting information, data storage rules, conversion information, time series information, and security and access information. The creation and maintenance of metadata starts with data modelling and continues to be enhanced and updated throughout the life of the data mart.
Mapping, Extracting, Aggregating, Loading (MEAL)
With the two data models in place it is time to start the MEAL. The first step is to map the data from the source (operational data) to the target database (data mart). Essentially, this step creates a cross reference, at the field level, of what data goes where.
Next, either by writing programs by hand or through the use of third-party tools, the data is extracted from the existing database, aggregated according to the data mart model and loaded into the data mart.
In an ideal world, these steps are relatively straight forward. Unfortunately, the simplicity of the process is thwarted by disparate data. Disparate data is data that is dissimilar in context and quality. There are two ways that data could meet these conditions. First, the values in the same field in a single file could be based on different assumptions. For example, consider a STATE field in a customer file. For most of us, we would assume that the state is just a two letter abbreviation of the address for that customer. But which address? Is the STATE associated with the shipping address or the billing address? It makes a difference if you are calculating the sales tax owed to a particular state. And you won't know the right answer unless you can peer into the minds of your users. This is data that differs in terms of context.
For an example of the differences in quality, consider the same STATE field as above. If you look at all of your customer records, it is unlikely that every record will have just two characters, each of which represents the state. Customers from outside the United States won't have an appropriate abbreviation. You may even find that the state code doesn't match the actual address due to some input error. Most of us don't have the error checking in place to ensure that the data is correct in every possible situation.
Disparate data has to be eliminated. You can either clean the data in your OLTP application or during the extraction process. Ideally, you would clean all of the existing data and fix the entry point that allows the inaccurate data to be entered in the first place. Practically, you will do most of the cleaning as part of the mapping and extraction process.
As you might have guessed, there is a great deal to consider when putting together a data mart. In the next issue, I will put together a list of best practices to consider, as well as some potential pitfalls to watch out for.
Sally Hober is a senior consultant at TAG Consulting, a consulting company that specialises in helping utilise computer systems to gain a competitive advantage. Sally has 7 years of experience in the MultiValue database (i.e. uniVerse, UniData and PICK) market. She specialises in the design and development of Data Warehouses, as well as technical training in many areas, including Data Warehousing, Managing Software Projects, uniVerse Objects and ODBC.
Sally was formerly a Technical Resource Manager and Consulting Project Manager at BLACKSMITH Corporation. While at BLACKSMITH, Sally was involved in managing large-scale software development projects and coordinating a staff of 11 analyst.
Sally Hober
TAG Consulting, Inc
Last Updated: 27 July 1999